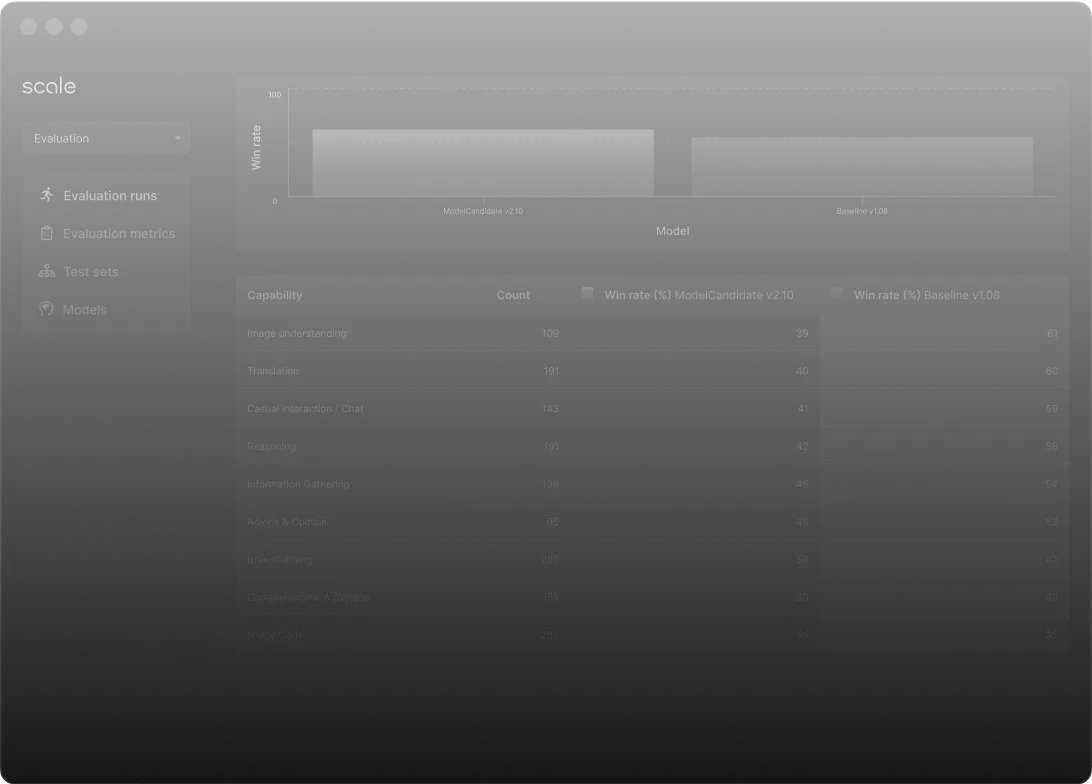
OpenWay Evaluation is a platform encompassing the entire test & evaluation process, enabling real-time insights on performance and risks to ensure AI systems are safe.
Bespoke GenAI Evaluation Sets
Unique, high-quality evaluation sets across domains and capabilities ensure accurate model assessments without overfitting.
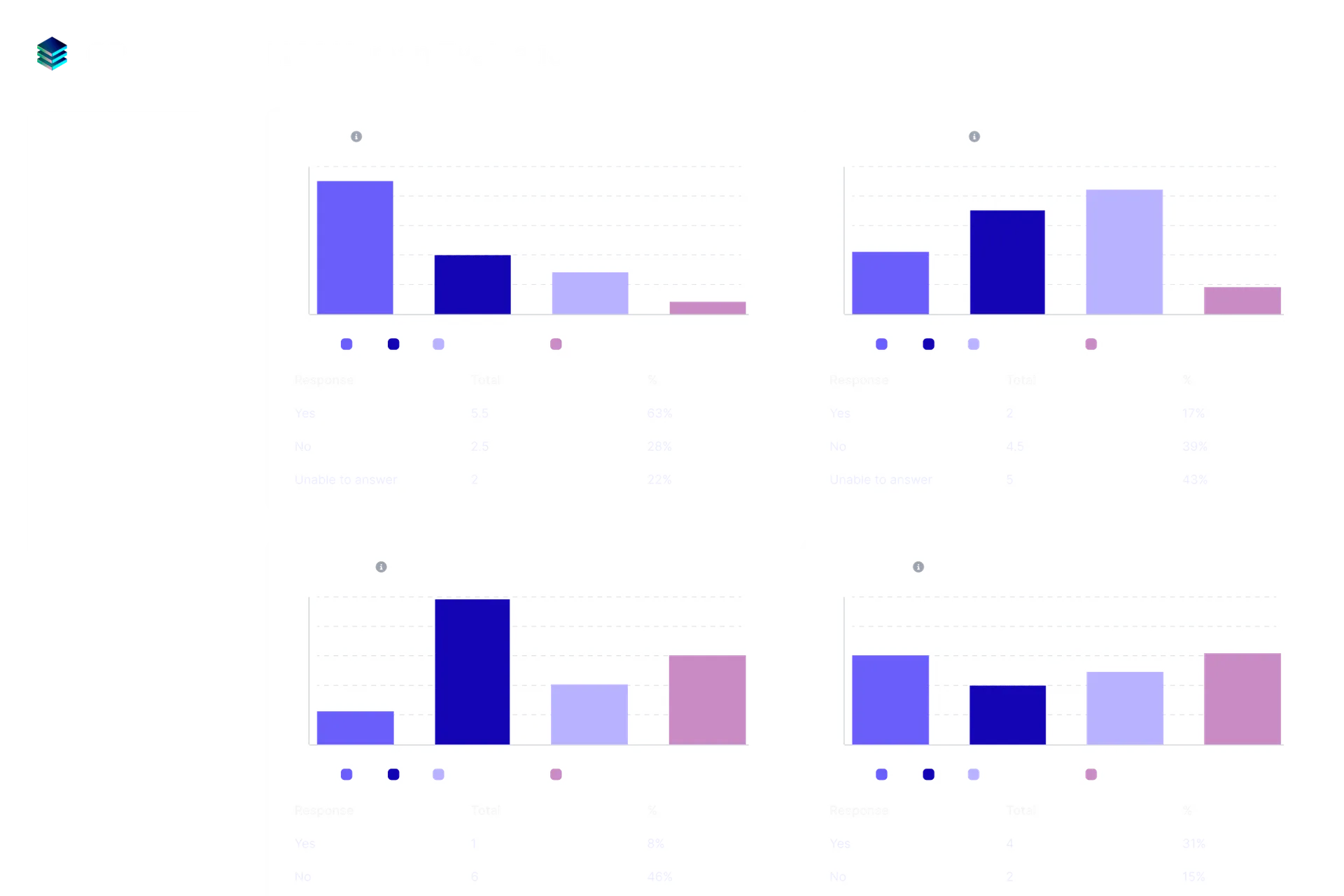
Rater Quality
Expert human raters provide reliable evaluations, backed by transparent metrics and quality assurance mechanisms.
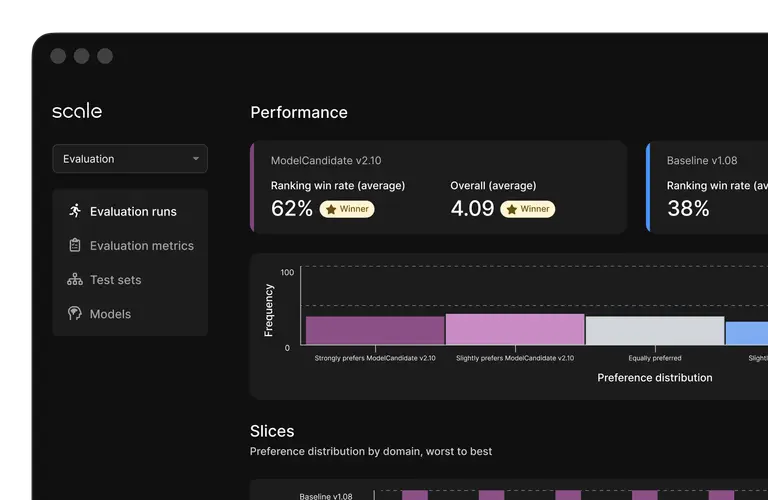
Reporting Consistency
Enables standardized model evaluations for true apples-to-apples comparisons across models.
Targeted Evaluations
Custom evaluation sets focus on specific model concerns, enabling precise improvements via new training data.
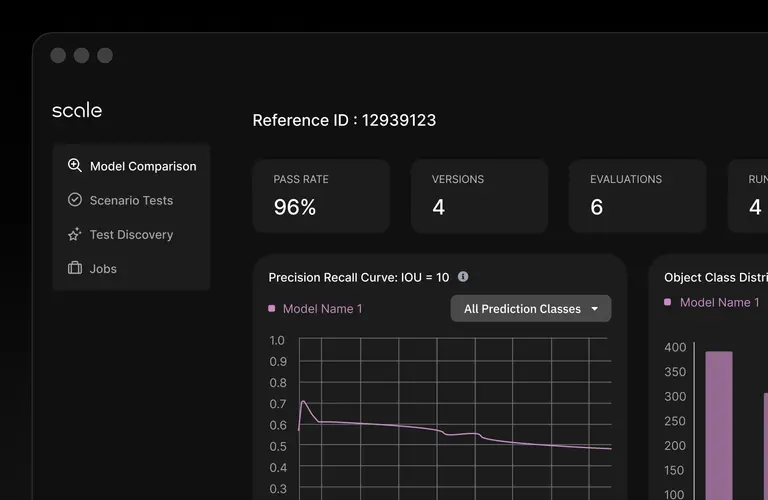
Product Experience
User-friendly interface for analyzing and reporting on model performance across domains, capabilities, and versioning.
Red-teaming Platform
Prevent generative AI risk or algorithmic discrimination by simulating adversarial prompts and exploits.